

A komplexitáselméletek megjelenése és kibontakozása, a digitalizáció, az új tudományterületek mint az adattudomány és a hálózattudomány jelentősen kiszélesítették a jog holisztikus, interdiszciplináris megközelítésének lehetőségeit mind empirikus, mind elméleti szempontból. Mindez az alapkutatásokon túlmenően is lehetővé teszi a jogrendszer mélyebb és kiterjedtebb kutatását, jelenségeinek mérését, akár valós idejű elemzését és megismerését, vagyis a jog fölmérését. Ez további lehetőségeket kínál mind újabb jogelméleti megközelítések megfogalmazására, mind pedig a joggyakorlatban közvetlenül hasznosítható következtetések levonására. A jogrendszer kiterjedt, minden részletére kiterjedő kutatása immár nemcsak lehetséges, de szükséges is ahhoz, hogy a jogrendszer a gyorsan változó környezeti kihívásokhoz megfelelő időben és kellő hatékonysággal tudjon alkalmazkodni, és ennek egyik záloga az intézményi kutatóintézetek megalapítása és működtetése. Az írás – amely leginkább szakmai módszertani megközelítésnek tekinthető – a komplexitáselméletekkel is összefüggésben, a technológiai fejlődési ívet felvillantva mutat rá az intézményi adatkutatás, valamint az intézményi kutatóintézetek jelentőségére.
I. Bevezetés
1. Adat, adat, adat: a megismerés kibontakozó távlatai
A tanulmány címe utalás Daniel Kehlmann A világ fölmérése című regényére,[1] amely a világ megismerésének két útjáról, az empirikus és az elméleti megismerésről szól; jelen írás vonatkozásában a jogrendszer digitális világban tükröződő jelenségei megismerhetőségének lehetőségeire utal. Tapasztalhatjuk, hogy a rendelkezésünkre álló technológiai és tudományos fejlődés következtében az élet valamennyi területén lehetőségünk nyílt a kiterjedt és mély megfigyelésre, és ezáltal a megfigyelés által olyan területek is összekapcsolódhatnak, amelyek egyébként korábbi felfogásunk szerint egymástól távol estek, vagy összefüggéseik eddig láthatatlanok voltak. Emiatt lehetővé vált, hogy ezek a területek, akár egyszerre is, összefüggéseikben, kölcsönhatásaikban és időbeli változásukban vizsgálhatók, megérthetők és leírhatók legyenek.
A datafikáció és a komplex rendszerelmélet találkozása a jogtudomány számára is szélesre tárta a kaput e megközelítések irányába, aminek fontosságát ma különösen kiemeli az a tény, hogy a jog, a jogrendszer és azon túl az azt magába foglaló teljes humán környezet összetettsége exponenciális mértékben nő. Fontos, hogy gyorsan változó környezetünk jelenségeit elfogulatlanul megítélve alkalmazkodjunk ehhez a változáshoz. Alapkutatások már ma is szép számmal akadnak, azonban kénytelenek vagyunk közelebbről vizsgálni a társadalmi jelenségeket, megkeresve azokat a lehetőségeket és módszereket, amelyek révén az új technológiai eszközök és elméletek leginkább előnyünkre fordíthatók. Ennek megfelelően a jog teljesebb felmérése is indokolt, és indokolt ehhez a rendelkezésre álló eszközöket minél szélesebb körben igénybe venni, ennek során pedig a jogrendszer folyamatait a vele kapcsolatos adatok keletkezésének helyén, valós időben vizsgálni. E kutatások a jogrendszer teljesebb megismerésének nélkülözhetetlen eszközei.
A jogrendszer maga is alrendszere egy olyan nagyobb társadalmi rendszernek, ami ugyancsak része egy még nagyobb rendszernek, és így tovább. A társadalmi rendszerek elemei, a rendszerek és alrendszerek egymással kölcsönhatásban, kölcsönös függőségben léteznek és fejlődnek, ami szükségessé teszi, hogy a jogot is interdiszciplináris megközelítésben vizsgáljuk. E folyamatban a különböző tudományterületi dogmatikák kölcsönhatásba kerülnek egymással, emiatt kénytelenek vagyunk összekapcsolni, egymáshoz képest magyarázni a különféle tudományterületi fogalmakat, ezáltal megtalálni a „közös nevezőket”. Így például, mivel a vázolt folyamatban a digitalizációnak kulcsszerepe van, a digitalizáció pedig elképzelhetetlen számok, sorbarendezés és összehasonlítás, azaz mérés nélkül, meg kell barátkoznunk a jog mérhetőségének gondolatával is.
A humán környezeti összetettség exponenciális mértékű növekedésének fő forrása az immár egyfajta életformaként is felfogott digitalizáció, azon belül pedig különösen az „első általános célú exponenciális technológia”,[2] vagyis a mesterséges intelligencia (a továbbiakban: MI vagy AI az angol megfelelő, artificial intelligence után). A digitalizáció joggal való egyre kiterjedtebb kölcsönhatásait a jogásztársadalom már a saját bőrén is tapasztalhatja, és e kölcsönhatások feltárása meghaladja ennek az írásnak a kereteit. Mindenesetre a társadalmi összetettség növekedése még inkább együttműködésre és új megközelítések alkalmazására kényszeríti a különböző tudományterületek, szakterületek kutatóit, ugyanakkor a digitalizációs forradalmak által kínált technológiák és új paradigmák a gyorsan növekvő digitális adathalmazokkal együtt biztosítják az összehangolt és kiterjedt kutatások lehetőségét, a komplexitáselméletek[3] segítségével pedig az összefüggések feltárhatóvá és leírhatóvá válnak. A címadó regényre utalással: mára kibontakozott egy másik, szintén fölmérésre váró világ, a kibertérben a fizikai világunk másaként leképezett digitális világ.
A digitalizáció révén egyre nagyobb tömegben keletkeznek digitális adatok a humán környezet minden területén (datafikáció),[4] amely adatok mozaikszerűen széttagolt adatbázisokban tárolódnak. Ha ezt a folyton bővülő digitális adathalmazt a mesék titkokat rejtő üveghegyeként képzeljük el, a valósághoz akkor állunk közelebb, ha elképzeljük, hogy éppen egy üveghegyekből álló magashegység felgyűrődésének (keletkezésének), vagy méginkább egy bolygó méretű digitális leképeződésnek vagyunk tanúi. És ebben az üveghegységben, ezen a digitális bolygón nem csupán a közvetlen környezetünk pillanatnyi jelenének felszíni képe, hanem a teljes környezetünk jelenének és múltjának felszíne és mélye egyaránt tükröződik. Ennek a képződménynek a kincsei pedig ugyanúgy a bányászat révén nyerhetők ki, mint a fizikai világ kincsei, jóllehet ez a bányászat nem nemesfémek és drágakövek, hanem a nem kevésbé értékes adatok után kutat.
Fontos kiemelni, hogy az adatoknak ez a felhalmozódása nemcsak kifejezett adatgyűjtési célt és szándékot feltételező folyamat eredménye, hanem ugyanúgy jellemző rá a kifejezett adatgyűjtésre irányuló szándék és cél nélküli adatképződés is, ami egyszerűen a digitalizáció természetéből fakad. A vizsgált adathalmazokról, különösen a rendezetlen adathalmazokról sokszor nem is tudjuk, hogy pontosan mit rejtenek, ezért sok esetben az elsődleges cél az adathalmazban felfedezhető mintázatok meghatározása, azután a felfedezett mintázatok mentén folyik tovább a kutatás.
Ugyanakkor a Big Data paradigma megjelenését követően a világon mindenütt egyértelműen tapasztalható egy olyan céltudatos adatgyűjtési törekvés, ami nem csupán egy-egy előre meghatározott terület adatait, hanem „minden” elérhető adatot céloz. Ebben a megközelítésben az adattudatos jogi gondolkodás és adatkutatás homlokterében sem az áll kizárólag, hogy meghatározza, milyen területről kíván adatokat gyűjteni, hanem az is, hogy megérti: ma már a jog minden területére jellemző a közvetett vagy közvetlen digitális adatképződés, és ennek az adatképződésnek a következményeként a digitális térben a jogrendszer képe is egyre részletesebben bontakozik ki előttünk. S egyre részletesebben is vizsgálható. Vagyis az adatokat már nem feltétlenül kell gyűjteni, mert egyre valószínűbb, hogy azok már léteznek valahol egy adatbázisban. Ellenben meg kell őket találni: erre való az adatkutatás. És hogy pontosan meg is értsük, hogy e kutatás során mit találtunk, valamint, hogy a talált adatokból helytálló következtetéseket vonhassunk le, szükséges az adatok legszélesebb értelemben vett kontextusainak ismerete, amely ismeretek nyilvánvalóan azokban az intézményekben állnak leginkább rendelkezésre, ahol a vizsgálandó adatok képződnek.
Ahogy a fizikai világ megismerése elképzelhetetlen mérés nélkül, úgy a digitális világ megismerése során sem mellőzhetjük ezt a módszert. Annál is inkább nem, mert maga a digitalizáció is elképzelhetetlen számolás, sorba rendezés és összehasonlítás, azaz mérés nélkül, ebből pedig levonható az a következtetés, hogy a digitális világban tükröződő jelenségek is mérhetők, sőt, éppen maga a digitalizáció kínálja föl a mérhetőség lehetőségét azokon a területeken is, ahol ez korábban nem volt általánosan elterjedt jelenség. Ilyen a jog területe is.
A jelenségek megismerésének ez a digitalizáció által kínált elképesztő részletességű lehetősége okozza ugyanakkor jelentős részben azt a félelmet is, amit a digitalizáció terjedése és a vele járó új paradigmák térhódítása a szellemi foglalkozást űző humán szakemberekben, így orvosokban, mérnökökben és persze jogászokban is kivált. A félelem attól, hogy a digitalizáció következtében az emberi tevékenység minden vonatkozásában mérhetővé, ennek következtében pedig algoritmizálhatóvá válik, és végül az ember munka nélkül marad. A magam részéről azonban úgy vélem, hogy ez a leegyszerűsítő gondolkodás nem számol a humán rendszerek valódi természetével, így a jogrendszer valódi természetével sem, amit egy másik írásomban igyekszem bizonyítani.[5] Ugyanakkor megjegyzendő, hogy a mérhetőség nem feltétlenül jelent kiszámíthatóságot, más megközelítéssel élve prediktálhatóságot.[6]
2. Big, Bigger and even Bigger Data
A jog területén képződő digitális adathalmaz ma már nem csupán a jogszabályokat, hanem egyre szélesebb körben a bírói ítéleteket, hatósági határozatokat, egyéb nyilvántartási adatokat, beadványokat, szerződések és nyilatkozatok szövegét, továbbá a jogi folyamatokhoz legváltozatosabb módon és közvetlenül kapcsolódó jogalanyi interakciók szöveges és egyéb, elektronikus adat formájában rögzülő nyomait is tartalmazza, amilyenek például az érkeztetési és egyéb naplózási adatok, telefonhívások, egyéb kommunikációs adatok, weboldalak adatai, különböző bejegyzések stb.
Az adatképződési folyamat során humán környezetünk intézményei a jogintézményeinkkel együtt tükröződnek a kibertérbe, majd kölcsönhatásba lépnek a fizikai világgal és megváltoztatják azt. Gondoljunk csak a digitális térben létező javak mint a kriptovaluták és egyéb digitális javak dologi minősége és tulajdonviszonyai kapcsán felmerülő kérdésekre, vagy a digitális személy, és ezzel kapcsolatban a felelősség problémakörére – már az ún. gyenge mesterséges intelligencia[7] kapcsán is, például az önvezető autókkal összefüggésben.[8] Vagy a digitális írásbeliséggel kapcsolatban felmerülő felvetésekre, és arra, hogy vajon ezek hatására hogyan változhat meg már a legközelebbi jövőben is a személyekről, felelősségről, a dologról, vagyonról és a tulajdonról vagy akár az írásbeliségről alkotott véleményünk. Hogy e kérdések ma már hazánkban is mennyire aktuálisak, jól tükrözik többek között a Klein Tamás és Tóth András által szerkesztett Technológia jog – robotjog – cyberjog című kötet robotjogi része[9] vagy az Udvary Sándor által a non-humán ágensekről írottak.[10]
Létezik tehát egy digitális tér, amelyben a fizikai világunk digitálisan rögzített adatok formájában egyre részletesebben tükröződik, és amelyben ezzel együtt a teljes humán környezet egyre részletesebb képe bontakozik ki, beleértve a jogrendszert is. Ennek a digitális adathalmaznak a növekedése vezetett el idővel a kutatásában rejlő lehetőségek felismerése következtében a Big Data kifejezés bevezetéséhez,[11] amelynek a jogra vonatkozó része jogi Big Data.[12] Ugyanakkor az MI, azon belül pedig a gépi tanulás (machine learning, deep learning)[13] révén rendelkezésre állnak azok az eszközök, amelyekkel ez az irdatlan adathalmaz keresztül-kasul átkutatható, előbb információvá, majd pedig tudássá alakítható. A korunk technológiai forradalmainak sorozata által kitermelt technológiák biztosítják, hogy a humán társadalmat és benne magát a jogrendszert is részletesebben, mélyebben és kiterjedtebben megismerhessük, mint ezelőtt bármikor.
De mit nevezünk tulajdonképpen Big Data-nak, mekkora ez az adathalmaz és mik a jellemzői? A Big Data nagyságával kapcsolatos vélemények eltérőek, de általában az egy terabyte-nyi adatot meg nem haladó adatmennyiséget nem szokás Big Datának nevezni. A több adat értelemszerűen pontosabb eredményekhez vezethet. Pusztán a mennyiség azonban nem elég. Az általános megközelítés szerint a mennyiség mellett ugyanolyan fontossággal bír két további tulajdonság is, nevezetesen az adatok változatossága (sokfélesége) és a gyorsaság. Vagyis, hogy az adathalmaz ne csupán nagy mennyiségű, hanem emellett változatos, illetve sokféle adatból álljon, egyúttal az adatok megszerzése és elemzése gyorsan, valós időben történjen meg, és lehetőleg azok keletkezése is folyamatos legyen (három V = volume, variety, velocity). A három V megközelítést alkalmazza Vespignani is a Big Datáról írva idézett könyvében, aki szerint a három V közül valójában az utóbbi ismérv, a gyorsaság adja a Big Data valódi értékét, nevezetesen azt, hogy használatának előnye az adatok újdonságából/frissességéből adódik, és azzal az információtöbblettel függ össze, amelyhez a jelen adatait a múlttal összehasonlítva jutunk.[14] Nem meglepő, ha egy komplex rendszerek kutatására specializálódott fizikus mint Vespignani, ilyen nagyra értékeli a gyorsaságot, a friss adatok valós idejű elemzését, tekintettel arra, hogy a komplex rendszerek önfejlődők, azaz folyamatosan változnak. A magam részéről – a jogi kutatások tekintetében legalábbis – egyet kell értenem Vespignanival, mivel a jog maga is komplex rendszer, mégpedig a szó természettudományos és természettudományokon túlmutató értelmében is az. A Big Data ismérveinek ez a hármas csoportosítása ugyanakkor más szerzők szerint több ismérvvel is kiegészül[15] úgy, mint a Veracity (valósághűség/megbízhatóság) és a Value (érték), amelyekre a cikk későbbi részében is utalni fogok.
1. ábra
A Big Data öt ismérve

Forrás: Hadi et al.: i. m. 20.
Ha a Big Data megközelítést a jogrendszer egészére és a jogrendszer folyamataira vonatkoztatjuk, kijelenthetjük, hogy valóban nagy mennyiségű adattal van dolgunk, és ha nem csupán a szövegeket, hanem az egyéb, naplózási és kommunikációs adatokat, hang- és videofájlokat is számításba vesszük, változatos adatmennyiséggel kell számolnunk. Valójában az adatok elérhetősége, az adatfeldolgozás sebessége, és a feldolgozás során az eredeti kontextusok figyelembevételének kiesése képezi e kutatások Achilles-sarkát, ami nyilvánvalóan kihat a kutatások értékére. Az elemzések során ugyanis csupán a hatályos jogszabályok adatai hozzáférhetők valós időben. A jogrendszeri folyamatokhoz kapcsolódó bírói ítéletek e folyamatokhoz képest csak hosszabb-rövidebb késéssel, 1-3 év múlva lesznek vizsgálhatók, – persze csak akkor, ha azokat digitalizálták -, és egyébként is jórészt a jogrendszeri anomáliák területére korlátozódnak, ugyanakkor az elemzés kevés kivétellel nem terjed ki a jogrendszeri folyamatok legnagyobb részére, határozatokra, beadványokra, nyilvántartási adatokra, szerződésekre és az ezekkel kapcsolatos egyéb digitális nyomokra, így hang- és videofájlokra vagy naplózási adatokra. Vagyis pusztán a hatályos jogszabályok és a bírói ítéletek elemzése a teljes jogrendszer megismerése szempontjából meglehetősen korlátozott lehetőségeket biztosít (persze ez attól is függ, hogy éppen mire irányul a kutatás).
A jogi adatelemzésben az adatkutatók által gyakorta hangoztatott probléma, hogy az elemzők sok esetben nem a saját maguk által előállított adatokat elemzik, hanem azokat be kell szerezniük valaki mástól, ami további időveszteséggel és egy másik problémával is jár, nevezetesen azzal, hogy az adatelemzés során elvész az adatok eredeti kontextusainak ismeretéből fakadó előny, amelyre lentebb vissza fogok térni. Az adatszerzésnek ez a módja ugyanakkor rendszerint megakasztja, sőt sok esetben ki is zárja az adatelemzés folyamatosságát, azaz folyamatos valós idejű elemzését. Ez pedig akár meg is kérdőjelezheti a Big Data szempontú megközelítés hasznosságát és értékét.
II. A jog holisztikus megközelítése
1. Komplexitástudomány és hálózatok
A társadalmi folyamatok digitális leképződésének ez a hatalmas léptékű kiterjedése, ami kaput nyit e jelenségek és folyamatok empirikus és elméleti megismerésének különböző lehetőségei előtt, kiterjeszti a jogi jelenségek holisztikus megközelítésének lehetőségét, ugyanakkor rámutat a jelenségek interdiszciplináris megközelítésének megkerülhetetlenségére. Ezzel még inkább felértékelődnek a jogszociológia, valamint a jog számos más, természettudományi indíttatású megközelítései, amelyek egy sokkal összetettebb, egymással részben versengő megközelítésekből és elméletekből álló halmazt képeznek. A jogrendszer e sokirányú megközelítését a hazai jogirodalomban jól tükrözi Jakab András és Sebők Miklós munkája,[16] amely a jogrendszer vizsgálata terén hagyományosnak tekinthető szociológiai, statisztikai, gazdaságelméleti megközelítéseken túl kitér többek között annak Big Data alapú, illetve hálózatelméleti elemzésére, valamint formális logikai és játékelméleti megközelítésekre is.
A jogrendszer e megközelítéseinek a legnagyobb lendületet, egyben e megközelítések elméleti alapját a 20. század második felében, a rendszerelmélet egy új irányzataként kibontakozó komplexitáselméletek, azok modern és posztmodern irányzatai adják, amelyek megjelenését általában a Santa Fe Intézet megalapításához (1984) kötik, és amely elméletek egyre több tudományterületen nyernek alkalmazást.
A komplexitáselmélet jogtudományi kölcsönhatásait jól tükrözik J. B. Ruhl, Daniel Martin Katz, Eric Kades, Donald T. Hornstein – és Michael James Bommarito – munkái,[17] továbbá a megközelítések tömör összegzését olvashatjuk Jamie Murray, Thomas E. Webb és Steven Wheatley művében, amelyben a szerzők egyúttal a posztmodern komplexitáselmélet talajáról kiindulva a luhmanni autopoietikus jogrendszermodell kritikáját fogalmazzák meg.[18] Ugyanakkor a szerzők nem jutnak el a komplex jogrendszermodell felvázolásáig, sőt, épp ellenkezőleg, Ruhl és Katz úgy foglalnak állást, hogy „éppen a posztmodern komplexitáselmélet alkalmazása miatt válik nyilvánvalóvá az, hogy arra a kérdésre: Mi a jogrendszer?, nincsen végleges válasz”.[19]
Mivel azonban a „Mi a jogrendszer?” kérdés éppen annak felmérése, azaz a vizsgálat tárgyának pontos meghatározása szempontjából mégsem megkerülhető, a modell létrehozására tettem egy kísérletet korábbi írásomban,[20] amelyben a jogrendszert, komplexrendszer-elméleti megközelítésben, közvetett és közvetlen kölcsönhatásai mentén dinamikus komplex rendszerként határozom meg, melynek közvetlen kölcsönható területeit mint hatályos normarendszer/pozitív jog (közhatalmi alapú normarendszer), mint parlament/hatóságok (közhatalmi alapú jogalkalmazás és normaképződés), mint bíróságok/alkotmánybíróság (közhatalmi alapú jogalkalmazás és normaképződés ), mint civil jogalkalmazás és normaképződés (nem közhatalmi alapú jogalkalmazás és normaképződés) és mint jogbölcselet (nem közhatalmi alapú normaképződés) azonosítom, amelynek többek között az adaptivitás és más komplexrendszer tulajdonságok a jogrendszer komplex volta miatt maguktól értetődő tulajdonságai.[21] Elfogadom Ruhl és Katz fent idézett véleményét annyiban, amennyiben a komplex rendszerek talajáról való megközelítés során a jogrendszer meghatározása esetében is valószínűségekkel és időszerűséggel vagyunk kénytelenek operálni, és a komplexitáselméleti alapú megközelítések valóban meghaladják az autopoietikus rendszerelméletet, mivel a jogrendszer működését és fejlődését, valamint az ezzel összefüggő tulajdonságait szélesebben és pontosabban képesek megragadni és leírni azáltal, hogy a jogrendszert kölcsönhatásaival együtt, működésében és időfejlődésében is képesek interpretálni. Ugyanakkor az idézett írásomban egy, a jogrendszert is magába foglaló nagyobb rendszeren belül világítok rá azokra a közvetlen kölcsönhatási viszonyokra, amelyekre gondolnunk célszerű akkor, ha a jogrendszerről beszélünk. Ez a kölcsönhatási rendszer pedig megvilágítja a jogrendszer határait, vagyis ennek alapján álláspontom szerint felvázolható egy komplex jogrendszermodell.
A komplexitáselméletek elterjedése magától értetődően magával hozta a komplex rendszerek nélkülözhetetlen vizsgálati módszerének, a hálózatanalízisnek az önálló tudománnyá, hálózattudománnyá való kifejlődését és széles körű alkalmazását nem utolsó sorban Duncan Watts és Steven Strogatz, illetve Barabási Albert-László és Albert Réka munkásságának köszönhetően. Ennek következtében pedig megindulhatott a jogrendszer hálózatkutatási eszközökkel való elemzése, ahogyan azt többek között Koniaris, Anagnostopoulos és Vassiliou Európai Unió jogforrásaira vonatkozó hálózatelemzése,[22] Bokwon Lee, Kyu Min Lee és Jae-Suk Yang dél-koreai alkotmánnyal kapcsolatos hálózatelemzése,[23] vagy Corinna Coupette, Janis Beckedorf, Dirk Hartung, Michael Bommarito és Daniel Martin Katz 2021 tavaszán publikált, az USA és Németország normarendszerén összehasonlító hálózatelemzése[24] mutatja. A jogi hálózatkutatás hazai eredményei köréből pedig példaként hozhatók fel Auer Ádámnak és munkatársainak kutatásai,[25] valamint Boldvai-Pethes Laura és Havelda Anikó kutatásai.[26]
2. Adattudomány és mesterséges intelligencia
Ahogyan a komplexitáselmélet teoretikus alapként szolgál a jogrendszer holisztikus megközelítéséhez, úgy ennek technológiai alapjait a digitalizáció és annak jelenségei, a Big Data, a neurális hálók (gépi tanulás, és annak ellenőrzött/supervised, ellenőrizetlen/unsupervised, valamint megerősített/reinforced módozatai, illetve ide sorolhatók az agyi emulációk terén végzett kísérletek is), összefoglaló néven az MI, továbbá az ennek következtében kifejlődött adattudomány (Data Science) biztosítja.
Ami a közhasználatban lévő MI fogalmakat és az ezekkel összefüggésben használt „machine learning”, „deep learning”, „neural network”, „agyi emulációk”[27] vagy „natural language processing”[28] kifejezéseket illeti – amelyek mind arra utalnak, hogy az MI megoldások lényegében az ember kognitív tulajdonságainak utánzását célozzák -, azok antropomorf vonatkozásai miatt gyakran okoznak félreértést, ami sok esetben a végletek felé tereli a közgondolkodást, rendszerint MI-optimista vagy MI-pesszimista irányba. Emiatt sokunkban az a képzet alakul ki az MI-vel kapcsolatban, mintha egy kiváltságos csoport által létrehozott valódi, az emberivel egyenértékű vagy azt meghaladó gépi intelligencia megalkotásáról lenne szó. Ez az elképzelés pedig jelentősen megnehezíti a realista megközelítést, miszerint a jelenkori MI esetében (azt nem lebecsülve) csupán olyan algoritmusokról van szó, amelyek matematikai és statisztikai eszközök révén próbálják leírni az emberi viselkedésformákat.[29] Az MI jog területén való értelmezésével kapcsolatban a hazai jogtudomány berkeiben sokirányú tudományos diskurzus zajlik, amit jól jellemeznek Klein Tamás írásai,[30] Ződi Zsolt[31] és Udvary Sándor[32] értekezései, vagy Auer Ádám,[33] Czékman Zsolt, Kovács László, Ritó Evelin[34] és számos más kutató munkái.
Nagyon egyszerűen és egyértelműen megfogalmazva, a mesterséges intelligencia napjainkban (és legalábbis a közeli jövőben) tulajdonképpen nem jelent mást, mint olyan fejlett statisztikai algoritmusokat, amelyeket emberek és algoritmusok közösen irányítanak.[35] Az adattudomány, a Big Data és a mesterséges intelligencia összefüggéseinek, valamint az adattudomány érdemi szakértelemmel, jelen esetben a jogtudományi ismeretekkel való összefüggéseinek megvilágítására szolgál a 2. és a 3. ábra.
2. ábra
A mesterséges intelligenciával átfedést mutató fogalmak

Forrás: Thakur: i. m.[36]
A 2. ábra halmazai által képzett közös halmazok szemléltetik, hogy az MI néven emlegetett jelenség lényegében egy hatalmas adatbázison (Big Data) működő, ezt az adatbázist elemző, a Machine Learning és a Deep Learning elvén működő algoritmusok összehangolt működése során előálló jelenség, melyről szerzett ismereteinket az adattudomány foglalja össze. A 3. ábra pedig azt szemlélteti, hogy az adattudomány fókuszában nem csupán a mesterséges intelligencia és a Big Data áll, hanem az kiterjed a matematikai és statisztikai tudás, a digitális rendszereket érintő ellenséges magatartások, és a digitális rendszerekkel érintett szakterületi tudás területeire is. E területek elsősorban az adattudományon keresztül lépnek kölcsönhatásba a 2. ábrán látható MI jelenséggel. Esetünkben pedig a jogtudomány az a szakterület, amely az adattudománnyal együtt közös halmazt alkotva áll kölcsönhatásban az MI-vel. Más szóval az MI és a 3. ábra szerinti három terület (benne a jogtudomány) közös halmazát az adattudomány képezi.
Összefoglalva, a jog területén képződő, jogi vonatkozású digitális adatok MI által történő elemzése és értelmezése során nélkülözhetetlenek a jogi ismeretek, és nem csupán az általános ismeretek, hanem azok a közvetlen joggyakorlati ismeretek is, amelyek tisztában vannak az adatok keletkezésének okaival és azok szélesebb kontextusaival is. Ezek hiányában ugyanis jelentősen sérülhet a kinyert adatok elemzésének pontossága.
3. ábra
Az adattudomány Venn-diagramja
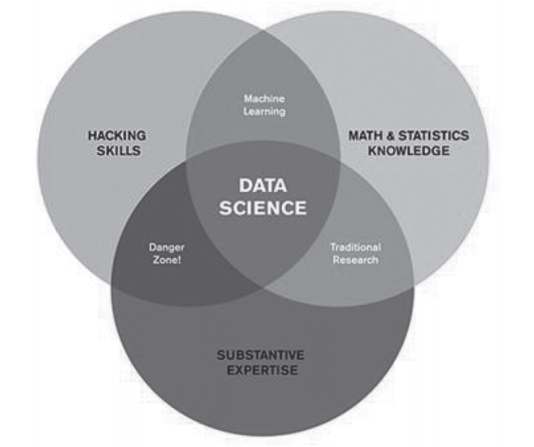
Forrás: Baldassarre: i. m.[37]
A jog területét érintő adatkutatások nem egyszerűen jogi ismereteket igényelnek, hanem ezen belül felértékelődik az a speciális szakterületi tudás is, amely a folyamatos és tényleges joggyakorlaton alapul. A jogrendszer folyamatainak ez a nagyon szoros és folyamatos tapasztalati, vagyis empirikus megismerése garanciát jelent arra, hogy egyrészt a fent jelzett kutatások kellő pontossággal és főként – a jog komplex rendszer voltára tekintettel – valós időben, szinte az adatok keletkezésével egy időben elvégezhetők legyenek, másrészt a kinyert adatok a valóságos, eredeti kontextusba helyezve nyerjenek értelmezést, és ezáltal pontosabb következtetésekhez vezessenek. Ezt indokolja a Big Data szempontú megközelítés gyorsasági követelménye (velocity) is, hiszen az az adatok leggyorsabb, valós idejű elemzését biztosíthatja, az adatok keletkezésének körülményeit és okait, továbbá azok előfordulásának területeit és szélesebb összefüggéseit pedig maga az adatokat előállító intézmény ismeri legjobban. Ezért az adatokat előállító intézmény a vizsgált adathalmazzal kapcsolatos kérdéseket (a keresési szempontokat) adott esetben pontosabban képes megfogalmazni és a kinyert információkat pontosabban képes értelmezni, mint azok a kutatók, akik az adatok előállításában nem vesznek részt. Ez a megközelítés pedig nem csupán a felügyelt gépi tanulás, hanem annak egyéb módjai mellett is előnyös, nemcsak a kérdésfeltevés, hanem a kinyert információk értelmezése területén is. Ez természetesen nem csökkenti az egyéb, nem adatelőállítók által végzett kutatások indokoltságát és hasznosságát, csupán az intézményeken belül előállított adatok belső kutatásainak előnyét hangsúlyozza, ami különösen fontos azokban az esetekben, amikor komplex rendszerek analíziséről van szó, ahol az azonnali és folyamatos hozzáférés, valamint a területspecifikus szakértelem nem megkerülhető. Ezek a tényezők pedig magyarázzák és alátámasztják az intézményi adatkutatás fontosságát.
A digitalizáció nem elképzelhető számolás, sorba rendezés és összehasonlítás nélkül, a mérés pedig a környezetünk jelenségeiről való ismeretszerzés egyik alapvető módszere, az empirikus megismerés alapja. Úgy is fogalmazhatunk, hogy a jogi digitalizáció megteremti a digitális világban tükröződő jogi jelenségek mérésének lehetőségét, vagyis lehetővé teszi a jog mérhetőségét.
A jogi folyamatok megfigyelése során a megfigyelt események tulajdonságait, a hozzájuk kapcsolódó megfigyelések eredményeit sorba rendezzük, majd azokhoz egy meghatározott szabály szerint számokat rendelünk, és ennek segítségével fejezzük ki valamely mennyiség nagyságát vagy arányát. Az eközben alkalmazott szabály határozza meg a mérés fő jellemzőjét, a mérési skála típusát, vagyis egy olyan értéksort, ami a megfigyelés során rögzített adatokat mennyiségi vagy az alkalmazott szabálytól függően akár minőségi viszonylatokba helyezi. Ezen az elven minősül mérésnek maga az adatgyűjtés és az adatfeldolgozás is, amelynek eredményei azután mennyiségi és minőségi összefüggések megállapításához vezethetnek, és a felismert újabb összefüggések alapján, a matematika és a logika módszereivel, valamint az emberi intelligencia révén további magállapításokat fogalmazhatunk meg.[38] Elmondható, hogy a fenti értelemben minden kvantitatív módszer alkalmazásával járó folyamatban jellemző a mérés, ami ugyanakkor a kvalitatív módszerek alkalmazása mellett is indokolt lehet. A digitális kor általános tanulsága, hogy bármely digitálisan rögzíthető és tárolható adat beilleszthető egy algoritmusba, amely algoritmus ezt az adatot a rendeltetése szerinti bármely célra felhasználhatja, így például a felhasználóval való interakció javítására vagy összefüggések, kölcsönhatások feltárására. Mindezek rámutatnak az adatok keletkezésének helyén található szakértelem fontosságára, mivel a helyes kérdésfeltevéshez, de még inkább a kinyert információk értelmezéséhez nem csupán arra van szükség, hogy tudjuk, a kinyert adat ott van, ahol éppen van, hanem arra is, hogy tudjuk, miért pont oda került, továbbá, hogy mik ennek a közvetlen és közvetett okai és mik ennek a további következményei.
A jogrendszer tapasztalás útján történő, vagyis empirikus megismerése előtt a digitalizáció és a komplexitáselméletek új távlatokat nyitnak, és teszik ezt akár olyan területeken is, mint például a Kulcsár Kálmán,[39] Gajduschek György,[40] Fekete Balázs,[41] Szilágyi István[42] és más kutatók nevével fémjelzett, többek között a jogismeret és jogtudat területét célzó kutatások, továbbá az élő jog területei, ahol a jogrendszer a jogalkalmazás révén a környezeti változásokhoz igazodva, azokat folyamatosan adaptálva fejlődik napról napra. A technológiai lehetőségek lehetővé teszik, hogy a jogi szövegek mélyére hatolhassunk, nagy részletességgel feltárva azok nyelvi összefüggéseit, egybevetve azokat a jogi folyamatokhoz kapcsolódó más minőségű adatokkal. Úgy is fogalmazhatnánk, hogy lehetővé válik a jogi eszmerendszernek mint általános, értékszempontú fogalomrendszernek a mérése, mivel az eszmerendszerek, így a jog is az emberi kultúrában, végső soron a nyelvben, a jog területére szűkítve pedig a jogi terminológiában gyökereznek. Az értékszempontú fogalomrendszerre/eszmerendszerre pedig kiváló példaként szolgálnak az alapjogokban megtestesülő eszmék, így az emberi élet, az emberi méltóság, a szabadság, a tulajdon eszméi, amelyek a pozitív normarendszerünk alapját képezik. A jogi szövegek és az azokhoz kapcsolódó egyéb adatok mozaikszerűen széttöredezve ugyan, de ma már rendelkezésre állnak a jogrendszer minden, fent vázolt területén. Gyakorta éppen ez a széttöredezettség az akadálya az elemzéshez szükséges korpuszok összeállításának.
A hasonlatként említett „Üveghegyek” vagy „digitális bolygó” tekintélyes részét teszik ki a jogrendszer által generált jogi relevanciájú adatok. A pozitív jog normái, a jogszabálygyűjtemények évtizedek óta elérhetők elektronikus formában bel- és külföldön egyaránt, a bírói ítéletek pedig egyre nagyobb számban állnak rendelkezésre. Emellett egyre nagyobb számban tárolódnak digitálisan – bár csupán az adatokat előállító intézmények számára elérhető módon – a különböző beadványok és a jogi folyamatokhoz kapcsolódó egyéb adatok, így egyre kiterjedtebben adnak lehetőséget a megfigyelésre és a mérésre, igaz a bíróságokat tekintve döntő részben a legsúlyosabb (a társadalom által semmiképp nem tolerálható) jogrendszeranomáliák területén.
Vagyis nem csupán a jogszabályok és bírói ítéletek, hanem az egyéb hatósági határozatok, illetve a jogalanyi kölcsönhatásokat tükröző szövegek, szerződések, jognyilatkozatok és egyéb adatok is egyre több vonatkozásukban mutatkoznak meg elektronikus adatok formájában, egyre bővülő különféle célú elektronikus adatbázisok állnak rendelkezésre. E területek mindegyike további jelentős digitális adatmennyiséget generál, amelyről nem állíthatjuk, hogy kizárólag problémamentes, bírósági gyakorlatban nem megjelenő esetekre utalnak. Ezekből az adatbázisokból részben hagyományos, egyszerűbb statisztikai elemzéssel, pusztán metaadatok vizsgálata útján, részben pedig összetettebb elemzési eszközökkel, a gépi tanulás valamely módszerével nyerhetők ki a szükséges adatok.
Ugyanakkor a szövegek a nyelven keresztül, szavak, szócsoportok, a gondolati összefüggések nyelvi kifejeződése révén hűen képesek tükrözni a jog eszmerendszerét, a jogrendszer intézményeit, a jog alanyainak interakcióit, és mindezek egymáshoz való viszonyulását, vagyis a jogrendszer kölcsönhatási viszonyait – különösen akkor, ha a vizsgált adatok a szövegeken kívül egyéb kapcsolódó adatokkal is kiegészülnek. E területen az NLP (Natural Language Processing, természetes nyelvfeldolgozás) technológiák – így az új, transformer alapú modellek, mint pl. a Google nyelvtani szabályokat is felismerő BERT nyelvi modellje, az OpenAI „nyelvi jóslásra”, vagyis szöveggenerálásra is alkalmas GPT2 (Generative Pretrained Transformer) és a százszor nagyobb méretű GPT3[43] verziói, vagy a Facebook AI research LASER (Language-Agnostic SEntence Representations) megoldása, valamint egyéb nyelvmodellező alkalmazások – és ezek tapasztalatai bizonyítják, hogy a szövegek legapróbb részletekbe menő elemzése és a szövegösszefüggések megfigyelése és összehasonlítása hatalmas tömegű irat esetében is lehetséges. Ezek az alkalmazások kiválóak a szemantikai kapcsolatok megértésében, de a puszta szemantikán túl nem képesek a lekérdezés és a dokumentum kifejezései közötti árnyaltabb kapcsolatokat megragadni. A Microsoft „Make Every feature Binary” (MEB) modell ugyanakkor képes tovább javítani a keresési relevanciát, vagyis a keresés pontosabbá és dinamikusabbá tétele érdekében a MEB e téren jobban kihasználja a Big Data által kínált lehetőségeket.[44] A hivatkozott modellek mindegyike alkalmas szöveggenerálásra (NLG, Natural Language Generation), amit egyre jobb minőségben produkálnak. Ugyanakkor a modellek alkalmazása nem áll meg a nyelv területén, hanem a közeli jövőben már egyfajta multimodalitásról is beszélhetünk, ahogyan azt a fejlesztés alatt álló, a GPT3 méretét ötszázszorosan meghaladó GPT4-gyel kapcsolatban olvashatjuk.[45]
Bár az itt felsorolt NLP eszközök nyelvfüggőségük folytán a hazai, magyar nyelvű adatbázisok tekintetében korlátozottan alkalmazhatók, és a „kis nyelvek” korlátozó hatása ma még hazai viszonylatban érezteti a hatását e területen, léteznek egyedi mérnöki megoldások arra, hogy ezek a vizsgálatok elvégezhetők legyenek. E területen a kvantitatív szövegelemzésre, szövegbányászatra (szöveganalitikára) remek hazai példát szolgáltat Bolonyi Flóra és Sebők Miklós munkássága.[46]
A hivatkozott megoldások akár a szövegek statisztikai elemzésén alapuló „jóslására”, azaz szöveggenerálásra is alkalmasak, vagyis képesek emberi beavatkozás nélkül összeállítani akár egy regényt vagy jogi szövegeket is bármely témával kapcsolatban, ha a tanuló adatbázisukban lévő adatok ehhez elegendő „muníciót”, azaz nyelvi alapanyagot szolgáltatnak. Ez azonban önmagában nem jelenti azt, hogy az így generált szöveg értelmes lesz egy frissen kibontakozó jogviszony esetében is. Az ilyen szöveggenerálás azt jelenti, hogy megállapítjuk: a témával kapcsolatban a múltban a generált szöveg szerinti adatok fordultak elő az adatbázisban szereplő iratokban. Egy leegyszerűsített példával élve, a világ összes digitalizált adásvételi szerződését elemzés alá vetve egy algoritmus képes lenne előállítani a világ „legtökéletesebb” adásvételi szerződését, de ez olyasmi lenne, mintha mondjuk, a világ legjobb ételét szeretnénk meghatározni statisztikai alapon. Az eredmény nagyon jó kiindulási alap lesz egy konkrét szerződés/jogviszony vagy étel felépítéséhez, de valószínűleg többé-kevésbé el fog térni attól a szerződéstől/jogviszonytól vagy ételtől, amit az épp jogviszonyba lépő konkrét felek (vagy a vacsoravendégek) aktuálisan akarnak. Persze, ehhez az is szükséges, hogy az érintett felek/vendégek tisztában legyenek azzal, hogy mi az, amit egyáltalán akarhatnak. És persze nem zárható ki olyan emberek létezése sem, akik képesek egész életükben kizárólag gyorséttermi hamburgeren, sült krumplin és cukrozott üdítőitalokon élni, akár tudatosan elzárkózva más lehetőségektől. Ezzel a példával talán valamelyest sikerült rávilágítani egyúttal arra is, hogy mi köze van a mesterséges intelligencia halmazába sorolt NLP technológiáknak a valódi, humán intelligenciához, és miért félrevezetőek az új technológiák antropomorf megközelítései.
És valóban, az élő, fejlődő rendszerekben, mint amilyen a jogrendszer is, a múltat, a múlt adatait folyamatosan a változó jelenhez kell alakítani. Ennek során, különösen egy gyorsan változó környezetben, figyelembe kell venni és be kell építeni, adaptálni kell az új, múltban még ismeretlen változókat és ez nem csupán az alkalmazkodásunknak, hanem a jogfejlődésnek is fontos feltétele. A felhozott példa szándékoltan egyszerű. Az egyszerűség indoka az, hogy rávilágítsak: a jog szempontjából fejlődését tekintve nem az az elsődleges kérdés, hogy a meglévő nyelvi nyersanyagból milyen kifinomult szövegeket lehet generálni, hanem az, hogy a gyorsan változó környezeti kölcsönhatásokat hogyan lehet a jogrendszerbe adaptálni.[47]
A fent hivatkozott alkalmazások (ágensek) tehát tulajdonképpen „sztochasztikus papagájokként”,[48] jóllehet nagyon szofisztikált papagájokként funkcionálnak, mindazonáltal jól szemléltetik, hogy a rendelkezésre álló technológia mire képes a digitalizált nyelvi nyersanyag elemzése terén. Vagyis azt, hogy e technológia segítségével milyen hatalmas kiterjedtséggel és mélységben válik megfigyelhetővé és elemezhetővé a nyelv, a vizsgálat alá vont szövegek, ami a jog szempontjából is kiterjedtebb és mélyebb kutatások lehetőségét rejti.
Ma már magyar nyelvű szövegek vonatkozásában is szaporodnak azok az egyedi megoldások, amelyek alkalmasak arra, hogy velük a jogi relevanciájú szövegeket nagy részletességgel és kiterjedtséggel „felboncolhassuk” és megfigyelhessük, és e megfigyelések alapján jogi relevanciájú nyelvi előfordulások topológiáit, dinamikus kölcsönhatási/kapcsolódási szerkezetét tetszőleges szempontok szerint felvázolhassuk, hogy azután azokból további következtetéseket vonhassunk le. Ez utóbbi feladatok továbbra is humán kutatókra várnak, hiszen az algoritmusok csupán az összefüggésekre mutatnak rá, anélkül azonban, hogy azokat „megértenék”.
A hivatkozott eszközök segítségével lényegében valamennyi nyelvfüggő jelenség, így a jogi eszmerendszernek a nyelvben jogi terminológiaként való megnyilvánulásainak összefüggései, a jogi eszméket megtestesítő jogintézmények, ezekkel együtt pedig a jogalanyok és kölcsönhatásaik, statisztikai, szemantikai alapú, időbeli vonatkozásai is megfigyelhetők, mérhetők és leírhatók. E mérések alapján a különböző fogalmakat, jogintézményeket, törvényi hivatkozásokat, jogterületeket, jogalanyokat, a jog bármely jelenségét hálózati csúcsokként meghatározva, kölcsönhatási jellemzőiket ún. élekként megadva felrajzolhatók a jogi rendszerének kölcsönhatási viszonyai (komplex hálózatai), amelyek a jogrendszer egyéb, szövegeken kívüli területeiről nyert adatokkal is összefüggésben akár hálózatkutatási,[49] akár egyéb adattudományi módszerekkel vizsgálhatók tovább. A jogrendszer ekként megvalósuló, minden területére kiterjedő mérése és elemzése hozzájárul ahhoz, hogy a jogrendszerről és annak folyamatairól a mainál pontosabb képet kapjunk. Erre utalnak a jogrendszerrel kapcsolatos eddig végzett, fent hivatkozott kutatások eredményei is, amelyek bizonyítják azt is, hogy a jogrendszerben is azonosíthatók a komplex rendszerekre jellemző, ún. skálafüggetlen hálózatok, igazolva egyúttal a jogrendszer komplex rendszer voltát. A kutatásokból a jogrendszer minőségére vonatkozó következtetéseket lehet levonni – álláspontom szerint ez teszi lehetővé a jog egyre pontosabb fölmérését.
3. A „Survivorship bias”[50]
A jogról alkotott teljesebb kép kialakításához és a jogi folyamatok pontosabb megértéséhez fontos, hogy a jog fölmérése a jogrendszer minden területére kiterjedjen. Ellenkező esetben téves következtetéseknek tehetjük ki magunkat, amit jól példáz a Wald Ábrahám[51] matematikus nevéhez köthető, az adattudomány területén jól ismert jelenség, a survivorship bias,[52] ami az elemzések során hiányzó adatok jelentőségére, az „elfogult” adatbázisokra hívja fel a figyelmet. A szóban forgó kifejezés mai szóhasználatunkban egy olyan logikai hiba, melynek során csak azokra az adatokra koncentrálunk, amiket ismerünk, de figyelmen kívül hagyjuk azokat az adatokat, amelyeket nem. Forenzikus megközelítésben: a bizonyítékok hiánya nem a hiány bizonyítéka.
A túlélési torzítás az emberi gondolkodás minden területén jelen van, így a jog területén is. Ugyanilyen logikai hibákhoz vezethet a jogról, jogrendszerről való gondolkodás és modellalkotás, ha a jogot, annak komplex rendszer voltát figyelmen kívül hagyva, csupán egy vagy csak néhány területéről közelítjük meg és magyarázzuk.
Témánkhoz térve, a jogrendszer megfigyelése és elemzése során az adatkutatások által eddig kevésbé érintett területek, mint például a nem-bírósági, hatósági jogalkalmazás és normaképződés, valamint a civil jogalkalmazás és normaképződés, azaz az Ehrlich, Kantorowitz és Gény – szabadjogi mozgalom[53] – neveivel fémjelzett élő jog területeire vonatkozó, ma már kiterjedt adatelemzéssel is támogatható kutatások ugyanolyan jelentőséggel bírnak, mint az ebből a szempontból szerencsésebb helyzetben lévő pozitív jog vagy a bírói jogalkalmazás és normaképződés kutatása. Bizonyosan állíthatjuk például azt, hogy az ingatlan adásvételi szerződésekkel kapcsolatos perek nem érintik az összes ingatlan adásvételi szerződést, feltehetően csak a szerződések igen kis hányadához kapcsolódnak. Ugyanakkor nyilvánvaló az is, hogy a bíróságot elkerülő esetekben sem zárhatók ki anomáliák. Így például egy csupán a hatályos jogszabályok és a vonatkozó bírói ítéletek adatait tartalmazó adatbázis az ingatlan adásvételi ügyletek összességének elemzése vonatkozásában elfogult adatbázisnak minősül, mert abból hiányoznak a bíróságokat elkerülő ügyek adatai. Ennek megfelelően az ilyen adatbázis elemzése torzított eredményekhez vezethet, ennek megfelelően csak korlátozott lehetőségeket biztosít.
III. Az intézményi kutatóintézetek szerepe a jog fölmérésében
1. Mozaikok és összkép
A különböző adatkezelő szervezetek kezén lévő adatbázisok ma már együttesen igen részletes és átfogó képet lennének képesek tükrözni az egész jogrendszerről, lehetővé téve e terület kiterjedt és mély, nem csupán metszet szerinti, hanem időben és térben kiterjedő mennyiségi és minőségi elemzését. Történelmünk során a technológia először kínál lehetőséget arra, hogy a jogrendszert a maga teljességében, térben és időben nagy részletességgel tanulmányozhassuk, megfigyelhessük és fölmérhessük. Lehetőségünk van megismerni az összképet, ám úgy tűnik, ennek legfőbb akadályát az adatbázisok mozaikszerű széttöredezettsége és az ebből fakadó adatszerzési nehézségek képezik. Ennek egyik fő oka az adatbázisok töredezettségén túl az adatokkal kapcsolatos fokozódó érzékenység, ami egyébként egyáltalán nem indokolatlan. Akkor mégis hogyan lehetséges ennek ellenére kiaknázni a vázolt lehetőségeket?
Ezek az euroatlanti régióban erősen védett, különböző hatósági és magán adatkezelő szervezetek által kezelt adatbázisok, akár egy darabokra tört tükör szilánkjai, tükrözik a jogrendszer folyamatait. Az összképet a tükörszilánkok képeit összeillesztve is kirakhatjuk, ami a különböző kutatóintézetek és kutatócsoportok összehangolt tevékenysége segítségével is megvalósítható. A probléma hazai viszonyok között megközelíthető akár a Nemzeti Adatvagyon Ügynökségen keresztül történő anonimizált adatigénylés útján is, azonban ezzel az eljárással az adatok elszakadnak eredeti kontextusaiktól, valamint elvész a „szakmai helyismeretből” fakadó, továbbá az adatelőállításhoz kapcsolódó speciális, szakterületi szakértelem is, és ezekkel együtt a komplex rendszerek elemzése során a Big Data paradigmához köthető egyik legfontosabb előny, az adatok valós idejű elemzésének a lehetősége.
2. Intézményi adatkutatás, a MOKK Adatkutató Alintézete
Úgy tűnik tehát, hogy a fenti előnyök megőrzése, és a Big Data paradigma legoptimálisabb kiaknázása érdekében célszerű közvetlenül az adatok keletkezésének/előállításának helyén, az adatkezelő intézményeken belül kutató intézeteket vagy kutatócsoportokat létrehozni, és ezek kutatásait összehangolni. E megfontolások vezettek a Magyar Országos Közjegyzői Kamara Adatkutató Alintézetének (MOKK Adatkutató, vagy Alintézet) létrehozásához 2020 nyarán.
Az Alintézet az általa kezelt adatokat kutatja és kutatásai összehangolására törekszik más adatkezelő szervezetekkel. Az Alintézet munkáját alapvetően a MOKK gyakorlati és tudományos szempontokat egyaránt magába foglaló adatstratégiája határozza meg, amelynek keretében több párhuzamos kutatás is folyik. Az adatkutatásnak ez a megközelítése az európai közjegyzőségek között jelenleg egyedülálló, jóllehet minden országban folyik hagyományos statisztikai értékelés.
A MOKK Adatkutató jelenleg folyamatban lévő kutatásai közül kettő éppen ilyen összehangolt kutatás, amelyek egyrészt az európai közjegyzői kölcsönhatási hálózatok feltérképezésére, másrészt az Európai Öröklési Rendelet[54] érvényesülésének sajátosságaira koncentrálnak. E kutatásokat az uniós tagállamok közjegyzői szervezeteinek adatkezelőivel, intézményeivel, illetve kutatócsoportjaival összehangoltan végezzük, oly módon, hogy az érintett szervezetek adatkezelőit bevonjuk az Alintézet által koordinált kutatásokba.
Az adatok keletkezésének helyén jellemző, fentiekben többször is említett területspecifikus szakértelem az adatkutatásban nem csupán azért fontos, mert ismeri, hogy a különféle adatok milyen adatbázisokban és hol találhatók, hanem sokkal inkább azért, mert tisztában van az adatok keletkezésének okaival és szélesebb kontextusaival, amelyek nem vezethetők le kizárólag a széles körben hozzáférhető hatályos jogi normarendszerből, hanem ismerni kell hozzá az adatképződés teljes környezetét, az adatforrások jellemzőit (így az adatforrások viselkedését, annak indokait, visszacsatolásaik jellemzőit stb.). Ezért nem nélkülözhetők e téren a joggyakorlati ismeretek. Például egy állampolgárságra utaló adat egész másra enged következtetni akkor, ha örökléssel, adózással vagy éppen jogérvényesítéssel kapcsolatban szerepel ugyanazon típusú okiratokban, és más szempontokat vet fel aszerint is, hogy jogi személyi, vagy természetes személyi körből származik-e az adat. Ugyanez a szakértelem szükséges ahhoz is, hogy az adatelemzést követően helyes információvá konvertáljuk a kinyert adatokat.
Természetesen ilyen speciális szakértelem hiányában is végezhető hasznos adatelemzés, azonban a területspecifikus szakértelem mind az adatok minőségét, mind az azokból levonható következtetések helyességét egyértelműen pozitív irányba befolyásolja, vagyis jelentős mértékben növeli a kutatás hasznosságát, teljesebbé teszi a Big Data paradigma alkalmazását. Ez az állítás a gépi tanulás minden módozatára érvényes, ugyanis a helyes kérdésfeltevés, vagyis a kutatási feltételek meghatározása, majd pedig a kinyert adatokból való információképzés egyaránt igényli az adatok eredeti kontextusainak pontos ismeretét, ami jelentősen támogatja az így szerzett információk helyes megítélését.
Az intézményi kutatóintézetek fontosságát emeli ki az a tény is, hogy ezek az intézmények valóban „real time”, azaz valós időben, folyamatosan detektálják a szakterületük folyamatait, ezért a Big Data-val kapcsolatos időszerűségi elvárásnak leginkább ők tudnak megfelelni. Az intézményi kutatóintézetek összehangolt kutatásai révén az eredményeket összesítve alakítható ki egy valósághoz pontosabban közelítő összkép. Ez a megoldás ugyanakkor egyrészt képes orvosolni az adatkutatók által emlegetett általános, a vizsgált korpuszok összeállításával kapcsolatos fent említett problémákat is, másrészt biztosíthatja, hogy egyetlen adatkezelő kezében se halmozódjon fel olyan kritikus tömegű adathalmaz, amelynek elemzése révén pusztán statisztikai alapon úgy is rá lehessen mutatni egyetlen konkrét személyre, hogy egyébként maga az elemzett adathalmaz egyáltalán nem tartalmaz érzékeny, konkrét személyekhez kötődő adatokat.
A MOKK Adatkutató fent hivatkozott, európai kölcsönhatási hálózat feltérképezésére irányuló vizsgálata során a kutatások összehangolása érdekében olyan adathalmazokra kellett rámutatni, amelyek egyrészt az EU tagállamaiban minden közjegyzőség számára elérhetők, függetlenül attól, hogy a digitalizáció milyen szintjén állnak, másrészt az elemzés szempontjából mindegyik tagállamban azonos összefüggésekre mutatnak rá. Ezen adati „közös nevezők” mentén indult meg az elemzés, amelynek első fázisán már túl vagyunk, azaz a hazai kölcsönhatásrendszer felmérése megtörtént. A kutatások előzményeiről és magáról a kutatásról bővebben beszámoltam egy korábbi,[55] valamint egy jelenleg megjelenés alatt álló[56] írásomban.
A kutatás megindítását egyébként az indokolta, hogy a határon átnyúló európai közjegyzői szolgáltatásokra ez ideig létrehozott digitális támogató rendszerek mint például a határon átnyúló ingatlanügyletekhez kapcsolódó EUFIDES vagy az európai kommunikáció támogatására létrehozott NotarNetwork, mindeddig nem váltották be a hozzájuk fűzött reményeket, mivel nem nyertek kiterjedt uniós szintű alkalmazást. A tényleges szolgáltatási hálózat feltérképezésével és a jelentős csomópontok (Hubok) meghatározásával a meglévő rendszerek fejlesztéséhez és új támogató rendszerek kialakításához kívánunk hozzájárulni, egyben rámutatni az európai jogharmonizáció gyakorlati szempontból kiemelkedő területeire.
A hivatkozott kutatás közvetlen gyakorlati haszna tehát abban áll, hogy az adatkutatás és hálózatelemzés révén rámutathatunk a szükséges és észszerű jogi és technológiai fejlesztési területekre és fejlesztési irányokra, ezeknek célszerű módjaira. Kimutathatóvá válnak például azok az európai csomópontok (tagállamok), amelyek a határon átnyúló jogi forgalom területén általánosan, vagy akár eljárásfajtánként kiemelkedő szerepet játszanak. Ebből kiindulva elemezhető ezen államok szabályozási és technológiai háttere, valamint az, hogy ez a háttér mennyiben segítette elő az adott tagállam, illetve tagállamok hálózati kiemelkedését.
Ha a szabályozási és alkalmazott technológiai háttér összefügg a tagállam kiemelkedő szerepével, úgy az uniós szintű szabályozás és a támogató rendszerek felépítése során célszerűbb a csomópontok jogi és technológiai megoldásaiból kiindulva szervezni a magasabb szintű rendszereket, mint a folyamatokat a nulláról indítani. A kutatás révén eljárásainkat európai szinten ügyfélközpontúbbá, gördülékenyebbé, gyorsabbá, hatékonyabbá tehetjük, ami nyilvánvalóan ki fog hatni a tagállamokon belüli közjegyzői szolgáltatásokra is. Ugyanakkor a kutatások az európai jogharmonizációs törekvések szempontjából is hasznosak, hiszen képesek rámutatni egyrészt a hatékonyabb jogi megoldásokra, másrészt a szabályozási szükségszerűségekre.
E kutatások során ugyanakkor nyilvánvalóvá váltak olyan, jogi folyamatokat érintő jellemzők (mintázatok) is, amelyek mindeddig rejtve maradtak a tudományos vizsgálatok előtt és amelyeket érdemes ebből a szempontból is feldolgozni. Például a kutatás egyik fázisában megmutatkozó örökléstervezési hajlandóság jellemzői alapján következtetéseket lehet levonni az adott jogterületre vonatkozó társadalmi jogtudatot illetően. Bár e tanulmány tárgyát tekintve egyfajta joggyakorlati programként fogható fel, talán a fentiekből is kitűnik, hogy a hivatkozott kutatási módszerek esetében nem mindig lehet és talán nem is mindig érdemes előre eldönteni azt, hogy azok vajon a jog elméleti/tudományos vagy gyakorlati megközelítéseit szolgálják-e, annál is inkább, mert a joggyakorlat és a jogelmélet nagyon szoros kölcsönhatásban áll/kell hogy álljon egymással, különösen egy olyan korban, amit exponenciális változások jellemeznek.
Ha ugyanis jelenünk igen gyorsan változó világában a jogelmélet nem képes azonnal detektálni a joggyakorlatban kibontakozó új jelenségeket, azt kockáztatja, hogy mire a véleményét kialakítja, vizsgálatának tárgya esetleg már nem is létezik, vagy úgy átalakul, hogy rá sem lehet ismerni. Ahhoz, hogy a jelenünk joggal szemben támasztott kihívásainak meg tudjunk felelni, a jog elméletének és a gyakorlatának egymással közvetlen, állandó és szoros kölcsönhatásban kell együttműködnie. Ami ugyancsak felhívja a figyelmet az adatok keletkezésének helyén történő adatkutatás, vagyis az intézményi adatkutatás fontosságára, mivel ezekben a kutatóintézetekben a tudományos és gyakorlati megközelítések közvetlenül és egyszerre, egymást támogatva képesek érvényesülni.
IV. Összefoglalás
A komplexitáselméletek megalapozzák és magyarázzák a jog holisztikus megközelítésének szükségességét, a széles értelemben vett digitalizáció pedig új lehetőségeket kínál e megközelítések kiteljesítésére. Ugyanakkor a jog, ez a komplex társadalmi alrendszer, maga is folyamatosan kölcsönhatásban áll a fent vázolt jelenségekkel, és többek között ezek hatására is nő komplexitásának mértéke. Ez a változás gyorsul.
Ahhoz, hogy a változáshoz a jog megfelelően alkalmazkodni tudjon; hogy az új technológiai vívmányokat helyesen és értékmegőrző módon használjuk fel a jog területén, és ahhoz, hogy mi magunk is alkalmazkodni tudjunk hozzájuk, részletesebben és kiterjedtebben kell megvizsgálnunk és megértenünk magát a jogot is. E megismerésre ugyanezek a forradalmi technológiai változások, és az ezekkel egyidejűleg kibontakozó elméletek és előálló eszközök teremtették és teremtik meg a lehetőséget, szélesebbre tárva a jog elméleti és empirikus megismerése lehetőségeinek kapuját, lehetővé téve egyben a jogi folyamatoknak és kölcsönhatásoknak, magának a jognak a teljesebb megfigyelését és felmérését.
A digitális adatbázisoknak, valamint a rendelkezésre álló adatkutatási technológiáknak és módszereknek köszönhetően a jogrendszer ma már tulajdonképpen minden régiójában, térben és időben is kiterjeszthetően megfigyelhető és növekvő pontossággal mérhető. A mérés által pedig maga a jogrendszer és a benne zajló folyamatok is modellezhetővé válnak, gondoljunk csak a jogi szövegek vonatkozásában alkalmazható nyelvi modellekre, vagy a jog területén végzett hálózatelemzésekre. A komplexitáselméletek és ezen elméletek kutatási módszereinek alkalmazása révén létrejön a hiányzó láncszem a jogtudomány és a természettudományok között, így a jog elméleti megközelítései az új módszerekkel is vizsgálhatóvá válnak.
A vázolt módszerek és paradigmák kiteljesítéséhez szolgáló információk új forrását a növekvő, egyben széttagolt digitális adatbázisok jelentik, ezért e folyamatban adatkutatás alapvető jelentőséggel bír. A fent hivatkozott okokból a rendelkezésre álló eszközök minél teljesebb kiaknázása, a pontos és minél értékesebb információszerzés érdekében a jognak ez a felmérése és az adatkutatás nem nélkülözheti a vizsgált jelenségekre és folyamatokra vonatkozó, az adatok keletkezésének helyén meglévő speciális szakismereteket, ezért e kutatásokban felértékelődik a tényleges joggyakorlati szaktudás és tapasztalat, ennek okán pedig a joggyakorlat képviselőinek részt kell vállalniuk ebben a folyamatban.
A felmérés folyamatában tehát nagy hangsúly helyeződik a jogi adatok keletkezésének helyén végzett kutatásokra, ennek pedig az egyik lehetséges és igen hatékony és ésszerű módját az összehangolt intézményi adatkutatások jelentik, amelyek az adatok keletkezésének helyén és idején, valós időben, a változásokat folyamatosan figyelemmel kísérve végzik az elemzéseket, és ennek során képesek az elméleti és gyakorlati szakterületi ismeretek legoptimálisabb összehangolására, erre szolgáltat példát a Magyar Országos Közjegyzői Kamara Adatkutató Alintézete.
JEGYZETEK
[1] Daniel Kehlmann: A világ fölmérése. Budapest, Magvető, 2006.
[2] Tilesh György – Hatamleh, Omar: Mesterség és intelligencia. Budapest, Libri, 2021. 85. Ez azért is figyelemre méltó megközelítés, mert igyekszik megszabadítani a jelenséget a zavaró, antropomorfizáló megközelítésektől.
[3] A komplexitáselméletek és a jog összefüggéseivel egy másik írásomban részletesebben foglalkozom, ezért ebben a tanulmányban a komplexitáselméletekkel, komplex rendszerekkel kapcsolatban erre a cikkre hivatkozom. Lásd Parti Tamás: Jog és komplexitás – egy komplex jogrendszermodell. Magyar Jog. 2021/9. sz. 538-551. és 2021/10. sz. 557-564.
[4] A datafikáció vagy adatosodás széles körben elterjed szóhasználat az elektronikus adatbázisok és a Big Data kapcsán, lényegében a környezetünkből származó digitális adatok felhalmozódására, a fizikai környezet digitális leképződésére utal, azaz egyre több digitális formában rögzített és tárolt adat áll rendelkezésünkre a világunkról. Ebben az értelemben használja a szót pl. az e cikkben idézett írásában Alessandro Vespignani fizikus is. Ez az adatosodási folyamat vezetett el a Big Data megjelenéséhez.
[5] Parti: i. m. (2021).
[6] A jog teljeskörű mérhetőségére és prediktálhatóságára vonatkozó közvetett utalások leginkább a technokrata érvelést jellemzik, ami legtöbbször információhiányból, a széles értelemben vett jogrendszer ismeretének hiányából fakad. Ugyanakkor a kapcsolódó jogi érvelés ritkán találja meg a közös nyelvet a technokráciával való hatékony kommunikációhoz, sok esetben ez vezet oda, hogy a jog érvei háttérbe szorulnak.
[7] A jog európai világában ma leginkább az Európai Parlament 2021. január 20-i mesterséges intelligenciáról kiadott állásfoglalása szerinti MI megközelítéssel találkozhatunk, mely szerint „A mesterséges intelligencia rendszer (MI rendszer): szoftveralapú vagy hardvereszközökbe ágyazott rendszer, amely intelligenciát szimuláló viselkedést mutat többek között adatok gyűjtése és feldolgozása, környezetének elemzése, valamint azáltal, hogy konkrét célok elérése érdekében – bizonyos mértékben autonóm módon – cselekszik”. A mesterséges intelligencia jelenség azonban akár tudományáganként is nagyon sok irányból közelíthető meg, és ennek megfelelően többféle értelmezést nyerhet és nyer, melyeknek ismertetése nem célja e tanulmánynak. Azt azonban ki kell emelni, hogy maga az MI megjelölés eredetileg sem tekinthető általános definíciónak, hanem arra vonatkozik, hogy egy-egy ilyen rendszer használata aktuálisan és technológiai értelemben milyen területekre irányul. Ezért az MI jelenséget érdemes a maga természete szerint, azaz technológiai oldalról megközelíteni, és ennek során lehetőleg szakítani az antropomorf megközelítésekkel, az MI-vel kapcsolatos legtöbb félreértést ugyanis éppen az antropomorf megközelítés okozza. A mesterséges intelligenciának általában három szintjét különböztetik meg, a ma ismert gyenge MI-t, amivel pl. a mobiltelefonjainkban vagy az önvezető autókban is találkozhatunk, a még nem, vagy legalábbis egyelőre nem létező általános, erős, vagyis az általános emberi intelligenciával egyenértékű MI-t (ÁMI) és a szuper, vagyis az emberi intelligenciát meghaladó MI-t. – lásd pl. Tegmark, Max: Élet 3.0. Budapest, HVG Könyvek, 2018. 152-178.
[8] Udvary Sándor: Az önvezető gépjárművek egyes felelősségi kérdései. Pro Publico Bono. 2019/2. sz. 146-155.
[9] Klein Tamás: Robotjog. In: Klein Tamás – Tóth András (szerk.): Technológia jog – robotjog – cyberjog. Budapest, Wolters Kluwer, 2018. 287-354.
[10] Udvary Sándor: A non-humán ágensek (intelligens rendszerek) jogi szabályozása – robotok, dedikált rendszerek (önvezető autók). In: Homicskó Árpád (szerk.): A digitalizáció hatása az egyes jogterületeken. Acta Caroliensia. Budapest, KRE ÁJK, 2020. 239-256.
[11] Mayer-Schönberger, Viktor – Cukier, Kenneth: Big Data. Budapest, HVG könyvek, 2014.
[12] Ződi Zsolt: A jogi szövegek mint big data. In: Jakab András – Sebők Miklós (szerk.): Empirikus jogi kutatások. Budapest, Osiris, 2020. 90-109.
[13] A machine learning vagyis gépi tanulás olyan algoritmusok használatát jelenti, amelyek egy adatsor betáplálását követően minták és kapcsolódások után kutatva az adatokban képesek önmaguktól tanulni. A machine learning algoritmusa a Neural network (neurális háló), ami lényegében az emberi agy leegyszerűsített modelljén alapul. Alapegysége a perceptron, azaz mesterséges neuron. A neurális hálók egységeinek halmazába adatokat táplálunk, amelyekkel ez az egység egyszerű számításokat végez, majd az eredményt a következő egységhez továbbítja, ami ugyancsak egyszerű számítások révén folytatja az adatfeldolgozást. A neurális hálók több, sőt nagyon sok rétegből állhatnak, a deep learning kifejezéssel ezekre a nagyon sok rétegből képzett neurális hálókra utalunk, amelyek a gépi tanulásnak egy sokkal szofisztikáltabb, „mélyebb” formáját képviselik. A gépi tanulás típusa szerint lehet supervised (felügyelt) tanulás, amikor az algoritmus a maga eredményeit veti össze a tanulás szakaszában helyesbített eredményekkel, unsupervised (nem felügyelt) tanulás, amikor az algoritmus egy adathalmazban anélkül keres mintázatokat és kapcsolódásokat, hogy azokat összevetné az eredmények összegével, valamint a reinforced (megerősített) tanulás, amikor az algoritmus lényegében a próbálkozásaiból és a hibáiból tanul. Lásd bővebben pl. Vespignani, Alessandro: A jóslás algoritmusa. Budapest, Libri, 2020. 75-89.
[14] Vespignani: i. m. 65-67.
[15] Ibtissame, Kandrouch – Yassine, Redouani – Habiba, Chaoui: Real time processing technologies in big data: Comparative study, 2017. Sept. 21-22, IEEE International Conference of Power, Control, Signals and Instrumentation Engineering (ICPCSI), az irat elérhető https://ieeexplore.ieee.org/abstract/document/8392202 (2021.10.18.). Hadi, Hiba Jasim – Shnain, Ammar Hameed – Hadishaheed, Sarah – Ahmad, Azizahbt Haji: Big Data and Five V’s Characteristics. International Journal of Advances in Electronics and Computer Science. 2015/1. sz. 20-21.
[16] Jakab András – Sebők Miklós (szerk.): Empirikus jogi kutatások. Budapest, Osiris kiadó, 2020.
[17] Ruhl, J. B.: Complexity Theory as a Paradigm for the Dynamical Law-and-Society System: A Weak-Up Call for Legal Reductionism and the Modern Administrative State. Duke Law Journal. 1996/5. sz. 849-928.; Ruhl, J. B.: Law’s Complexity: A Primer. Georgia State University Law Review. 2008/4. sz. 885-911. https://heinonline.org/HOL/LandingPage?handle=hein.journals/gslr24&div=45&id=&page= (2021.10.18.); Katz, Daniel – Ruhl, J. B.: Measuring, Monitoring, and Managing Legal Complexity. Iowa Law Review. 2015/1. sz. 191-244.; Katz, Daniel Martin – Bommarito, Michael James: Measuring the Complexity of the Law: The United States Code. Artificial Intelligence and Law. 2014/4. sz. 337-374. (2021.10.18.); Kades, Eric: The Laws of Complexity & the Complexity of Laws: The Implications of Computational Complexity Theory for the Law. Rutgers Law Review. 1997/2. sz. 403-484. https://scholarship.law.wm.edu/facpubs/646 (2021.10.18.); Hornstein, Donald T.: Comlexity Theory, Adaptation and Administrative Law. Duke Law Journal. 2005/4. sz. 913-960. https://heinonline.org/HOL/LandingPage?handle=hein.journals/duklr54&div=29&id=&page= (2021.10.18.).
[18] Murray, Jamie – Webb, Thomas E. – Wheatley, Steven: Encountering law’s complexity. In: Murray, Jamie – Webb, Thomas E. – Wheatley, Steven (eds.): Complexity Theory and Law. London, Routledge, 2019. 6-7.
[19] Ruhl, J. B. – Katz, Daniel M.: Mapping law’s complexity with „Legal Maps”. In: Murray, Jamie – Webb, Thomas E. – Wheatley, Steven (eds.): Complexity Theory and Law. London, Routledge, 2019. 23.
[20] Parti: i. m. (2021).
[21] Lásd bővebben Parti: i. m. (2021).
[22] Koniaris, Marios – Anagnostopoulos, Ioannis – Vassiliou, Yannis: Network analysis in the legal domain: a complex model for European Union legal sources. Journal of Complex Networks. 2018/2. sz. 243-268. DOI: 10.1093/comnet/cnx029
[23] Lee, Bokwon – Lee, Kyu-Min – Yang, Jae-Suk: Network structure reveals patterns of legal complexity in human society: The case of the Constitutional legal network. PLoS ONE. 2019/1. sz. DOI: 10.1371/journal.pone.0209844
[24] Coupette, Corinna † – Beckedorf, Janis † – Hartung, Dirk – Bommarito, Michael – Katz, Daniel Martin: Measuring Law Over Time: A Network Analytical Framework with an Application to Statutes and Regulations in the United States and Germany. Frontiers in Physics. 28 May 2021. DOI: 10.3389/fphy.2021.658463
[25] Auer Ádám – Joó Tamás (szerk.): Hálózatok a közszolgálatban. Budapest, Dialóg Campus, 2019.
[26] Boldvai-Pethes Laura – Havelda Anikó: Hálózatkutatás. In: Jakab András – Sebők Miklós (szerk.): Empirikus jogi kutatások. Budapest, Osiris, 2020. 347-361.
[27] Lida, Masahito: Artificial General Intelligence Part 3. A world where AI provides humans with close support through super-human intellect – Development of Brain-Inspired AGI. 15 May 2020. https://www.mri.co.jp/en/50th/columns/ai/no03/ (2021.10.18.). Az agyi emulációk, vagyis az emberi agy számítógépes modellezésére tett kísérletek ugyancsak az emberi intelligencia modellezését célozzák, így annak fejlesztői abban az erős, vagyis a humán szintű MI kifejlesztésének egyik módját látják. Bostrom, Nick: Szuperintelligencia. Budapest, Ad Astra, 2015. 59-67.
[28] Az NLP vagyis natural langue processing/természetes nyelvfeldolgozást célzó technológiák a természetes nyelv elemzésére, modellezésére szolgáló alkalmazások.
[29] Vespignani: i. m. 75.
[30] Klein: i. m. (2018); Klein Tamás: Robotjog vagy emberjog? Az emberközpontú mesterséges intelligencia szabályozásának kiindulási pontjai. In: Török Bernát – Ződi Zsolt (szerk.): A mesterséges intelligencia szabályozási kihívásai: Tanulmányok a mesterséges intelligencia és a jog határterületeiről. Budapest, Ludovika Egyetemi Kiadó, 2021. 111-142.
[31] Ződi, Zsolt: What Will Robot Laws Look Like? The Code of AI and Human Laws. Acta Universitatis Sapientiae Legal Studies. 2019/2. sz. 253-268.; Ződi Zsolt: Az Európai Bizottság Mesterséges Intelligencia Kódexének tervezete. Gazdaság és Jog. 2021/5. sz. 1-3.
[32] Udvary Sándor: Az autonóm nem emberi cselekvés polgári jogi megítélésének egyes kérdései az automatizált döntéshozatal adatvédelmi szabályainak határvonalán. In: Török Bernát – Ződi Zsolt (szerk.): A mesterséges intelligencia szabályozási kihívásai: Tanulmányok a mesterséges intelligencia és a jog határterületeiről. Budapest, Ludovika Egyetemi Kiadó, 2021. 423-437.; Udvary Sándor: A mesterséges intelligencia, mint potenciális adatvédelmi jogsértő. Acta Universitatis Szegediensis Acta Juridica et Politica. 2021/3. sz. 451-456.
[33] Auer Ádám: Godolatok a mesterséges intelligencia egyes polgári jogi kérdéseiről. Scientia et Securitas. 2021/2. sz. 106-113.
[34] Czékmann Zsolt – Kovács László – Ritó Evelin: A mesterséges intelligencia alkalmazásának lehetőségei az államigazgatásban. Infokommunikáció és Jog. 2020/2. E-különszám. https://infojog.hu/kovacs-laszlo-czekmann-zsolt-rito-evelin-a-mesterseges-intelligencia-alkalmazasanak-lehetosegei-az-allamigazgatasban-2020-2-75-e-kulonszam/ (2021.10.18.)
[35] Firth-Butterfield, Kay – Kwartler, Ted – Kharty, Sarah: It’s time to change the debate around AI ethics. Here’s how. https://www.weforum.org/agenda/2021/07/why-it-s-time-to-change-the-debate-around-ai-ethics/ (2021.07.25.)
[36] Thakur, Naresh: The differences between Data Science, Artificial Intelligence, Machine Learning, and Deep Learning. Artificial Intelligence in Plain English. 2020. 04. 17. https://ai.plainenglish.io/data-science-vs-artificial-intelligence-vs-machine-learning-vs-deep-learning-50d3718d51e5 (2021.10.18.)
[37] Baldassarre, Michele: Think big: learning contexts, algorithms and data science. REM – Research on Education and Media. 2016/2. sz. DOI: 10.1515/rem-2016-0020, https://www.researchgate.net/figure/The-Venn-diagram-for-data-science-graphic-by-author-based-on-Conway-2010_fig7_313020352 (2021.10.18.)
[38] Simon Károly: A fizika kultúrtörténete. Budapest, Akadémiai Kiadó, 2011.
[39] Kulcsár Kálmán: A jogismeret vizsgálata. Budapest, MTA JTI, 1967.
[40] Gajduschek György: Empirikus jogtudat kutatás Magyarországon 1990 után. MTA Law Working Papers. 2016/11.
[41] Fekete Balázs – H. Szilágyi István: Jogtudat-kutatások a szocialista Magyarországon. Iustum Aequum Salutare. 2014/4. sz. 5-40.
[42] H. Szilágyi Isván: A jogtudat-kutatások elméleti kérdései. Iustum Aequum Salutare. 2017/1. sz. 15-36.
[43] Hutson, Matthew: Robo-writers: the rise and risks of language-generating AI – A remarkable AI can write like humans – but with no understanding of what it’s saying. 03 March 2021. https://www.nature.com/articles/d41586-021-00530-0 (2021.10.18.) Ha megfelelően komplex és nagy az adatbázis, akkor nagyobb méretű modell jobb tanulási eredményeket produkál.
[44] Chen, Junyan – Li, Jason (Zengzhong) – Majumder, Rangan: Make Every feature Binary: A 135B parameter sparse neural network for massively improved search relevance. Microsoft Research Blog. https://www.microsoft.com/en-us/research/blog/make-every-feature-binary-a-135b-parameter-sparse-neural-network-for-massively-improved-search-relevance/ (2021.10.18.) Az alkalmazott neurális háló méretéről és képességeiről árulkodik, hogy az több mint 200 milliárd bináris funkcióval rendelkező beviteli funkciót (paramétert) tesz lehetővé, tanulóbázisát több mint 500 milliárd lekérdezés/dokumentum pár képezi, és a legújabb verzió 9 milliárd funkcióval és több mint 135 milliárd paraméterrel rendelkezik.
[45] Romero, Alberto: GPT-4 Will Have 100 Trillion Parameters – 500x the Size of GPT-3 Are there any limits to large neural networks? https://towardsdatascience.com/gpt-4-will-have-100-trillion-parameters-500x-the-size-of-gpt-3-582b98d82253 (2021.10.18.)
[46] Bolonyai Flóra – Sebők Miklós: Kvantitatív szövegelemzés és szövegbányászat. In: Jakab András – Sebők Miklós (szerk.): Empirikus jogi kutatások. Budapest, Osiris, 2020. 365-377.
[47] Lásd bővebben Parti: i. m. (2021).
[48] Bender, Emily M. – Gebru, Timnit – McMillen-Major, Angelina – Shmitchell, Shmargaret: On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? https://faculty.washington.edu/ebender/papers/Stochastic_Parrots.pdf (2021.07.29.)
[49] Barabási Albert-László: Hálózatok tudománya. Budapest, Libri, 2016.
[50] Túlélési torzítás.
[51] A Kolozsváron (1902) született Wald Ábrahám, matematikus, a matematikai statisztika, döntéselmélet, játékelmélet művelője, a modern statisztika és ökonometria megteremtésének egyik vezéralakja, akinek a nevéhez többek között a survivorship bias, a Wald teszt és a Wald egyensúly is köthető. David McRenay szerint korának legnagyobb statisztikusa.
[52] A második világháború alatt Wald Ábrahám az Amerikai Egyesült Államokban egy statisztikai kutatócsoport tagjaként dolgozott. Wald csoportjának kutatásai kiterjedtek többek között a vadászgépek védelmi rendszereinek optimalizálását célzó folyamatokra is. A vadászgépeket páncéllal kellett védeni az ellenséges találatokkal szemben. A páncél viszont megnövelte a repülőgép súlyát, ami hátrányt jelentett, mert manőverezési nehézségeket, magasabb üzemanyagfogyasztást és többletköltségeket okozott, nem beszélve a háborús időkre jellemző erőforráshiányról. Az eredményességet tehát a költségek csökkentése mellett kellett növelni. A valódi kérdés a páncél optimális vastagsága és elhelyezése volt. Ennek az optimumnak a kidolgozása volt Waldék egyik feladata. Úgy tűnt, hogy az adatok forrását képező visszatért gépek legsérülékenyebb pontja maga a törzs volt (ezt érte a legtöbb találat). Ennek megfelelően a tisztek a törzs páncélzatának megerősítését javasolták, míg a kevesebb találatot érő részeken gyengíteni akarták a páncélzatot. Wald azonban más véleményen volt. Ott javasolta erősíteni a páncélt, ahol kevesebb a sérülés, vagyis a hajtóművek páncélzatának megerősítését kérte a törzs páncélzatának rovására. Döntését pedig azzal indokolta, hogy az a gép, melynek hajtóművét több találat érte, nem tért vissza a bázisra, vagyis lezuhant, míg az a gép, melynek a törzse sérült, visszatért az ütközetből, vagyis harcképesebb maradt. Tehát valójában a hajtómű a gyenge pont. Wald a sérülések eloszlásából indult ki, feltételezve, hogy azok valódi eloszlása egyenletes. Ugyanakkor a visszatért gépek sérüléseinek eloszlása nem volt egyenletes. Ennek megfelelően azokat a sérüléseket kereste, amelyek hiányoztak, azaz amelyeket figyelembevéve a találatok egyenletesen oszlanának meg. Ezek a találati sérülések pedig azokon a gépeken lettek volna megfigyelhetők, amelyek kimaradtak a vizsgálatból, mivel lezuhantak. A tisztek tévedése abban állt, hogy azt feltételezték, minden gép túlélési valószínűsége azonos. A valóságban azonban a lövedékek által okozott sérülések elhelyezkedése arányos a túlélési eséllyel. Kása Zoltán – Oláh-Gál Róbert: Az ismeretlen Wald Ábrahám. Csíkszereda-Kolozsvár, 2020. 13-16. https://www.researchgate.net/publication/346036051_Az_ismeretlen_Wald_Abraham_The_Unknow_Abraham_Wald (2021.07.29.)
[53] Takács Péter: A szabadjogi mozgalom jelentősége a jogszociológiában és a jogelméletben. 2017. 7-15. https://jet.sze.hu/images/Jogszociológia/~%20A%20SZABADJOGI%20MOZGALOM%20-%202%20előadás%20-%202017%20február%2013%20.pdf (2021.09.15.)
[54] Az Európai Parlament és a Tanács 650/2012/EU rendelete (2012. július 4.) az öröklési ügyekre irányadó joghatóságról, az alkalmazandó jogról, az öröklési ügyekben hozott határozatok elismeréséről és végrehajtásáról, valamint az öröklési ügyekben kiállított közokiratok elfogadásáról és végrehajtásáról, valamint az európai öröklési bizonyítvány bevezetéséről, HL L 201., 2012.7.27., 107-134.
[55] Parti Tamás: Közjegyzői hálózatok az Európai Unióban. Közjegyzők Közlönye. 2019/4. sz. 1.
[56] Parti Tamás: A közjegyzői szolgáltatások európai kölcsönhatásrendszere, határon átnyúló közjegyzői szolgáltatások. Megjelenik a Közjegyzők Közlönye 2021/3. számában.

